nearneighbor¶
Ici vous aurez des explications sur la commande et ses différents paramètres.
pygmt.nearneighbor(data=None, x=None, y=None, z=None, \*, empty=None,
outgrid=None, spacing=None, sectors=None, region=None,
search_radius=None, verbose=None, aspatial=None, binary=None,
nodata=None, find=None, coltypes=None, gap=None, header=None,
incols=None, registration=None, wrap=None, \**kwargs)
Utilité :¶
Le traitement de données en grille en utilisant l’algorithme du « plus proche voisin ».
La commande « nearneighbor » lit des triplets (x, y, z[, w]) arbitrairement situés [quadruplets] et utilise un algorithme du plus proche voisin pour attribuer une valeur moyenne pondérée à chaque nœud qui possède un ou plusieurs points de données à l’intérieur d’un rayon de recherche centré sur le nœud avec une couverture adéquate dans un sous-ensemble des secteurs choisis. La valeur du nœud est calculée comme la moyenne pondérée du point le plus proche de chaque secteur à l’intérieur du rayon de recherche. La fonction de pondération et la méthode de calcul utilisée sont les suivantes :
où \(n\) est le nombre de points de données qui satisfont les critères de sélection et \(r_i\) est la distance entre le nœud et le \(i\) ème point de données. Si aucun poids de données n’est fourni, les poids sont égaux à \(w_i = 1\).
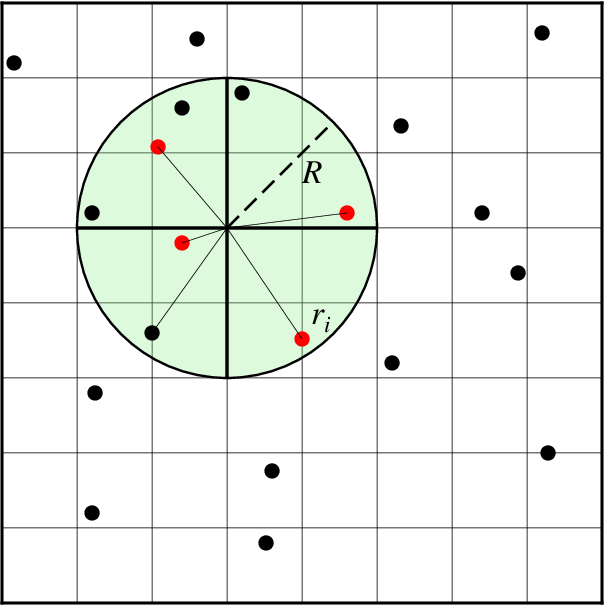
La géométrie de recherche comprend le rayon de recherche (R), qui limite les points pris en compte, et le nombre de secteurs (ici 4), qui restreint la contribution des points à l’intérieur du rayon de recherche à la valeur du nœud. Seul le point le plus proche dans chaque secteur (cercles rouges) contribue à l’estimation pondérée.
Prend en entrée une matrice, des triplets (x, y, z) ou le nom d’un fichier.
Il est nécessaire de fournir soit les données, soit les coordonnées x, y et z.
Paramètres :¶
data (str ou numpy.ndarray ou pandas.DataFrame ou xarray.Dataset ou geopandas.GeoDataFrame) - Fournit des valeurs (x, y, z) ou (longitude, latitude, élévation) en fournissant le nom d’un fichier contenant une table de données ASCII, un tableau numpy.ndarray 2D, un pandas.DataFrame, un xarray.Dataset composé de variables de données xarray.DataArray 1D, ou un geopandas.GeoDataFrame contenant les données tabulaires.
x/y/z (tableaux 1D) - Tableaux des coordonnées x et y et des valeurs z des points de données.
spacing (str) - x_inc[+e|n][/y_inc[+e|n]]. x_inc [et éventuellement y_inc] est l’espacement de la grille.
Coordonnées géographiques (degrés) : Facultativement, ajoutez une unité d’incrément. Choisissez parmi m pour indiquer les minutes d’arc ou s pour indiquer les secondes d’arc. Si l’une des unités e, f, k, M, n ou u est ajoutée à la place, l’incrément est supposé être donné en mètre, pied, kilomètre, mile, mille marin ou pied d’étalonnage US respectivement, et sera converti en degrés de longitude équivalents à la latitude moyenne de la région (la conversion dépend de PROJ_ELLIPSOID). Si y_inc est donné mais défini à 0, il sera réinitialisé à x_inc ; sinon, il sera converti en degrés de latitude.
Toutes les coordonnées : Si +e est ajouté, la valeur maximale correspondante de x (est) ou y (nord) peut être légèrement ajustée pour correspondre exactement à l’incrément donné [par défaut, l’incrément peut être légèrement ajusté pour correspondre au domaine donné]. Enfin, au lieu de donner un incrément, vous pouvez spécifier le nombre de nœuds souhaité en ajoutant +n à l’argument entier fourni ; l’incrément est ensuite recalculé à partir du nombre de nœuds, de l’enregistrement et du domaine. La valeur d’incrément résultante dépend de la sélection d’une grille enregistrée par ligne de grille ou enregistrée par pixel ; voir les formats de fichier GMT pour plus de détails.
Remarque : Si region=grdfile est utilisée, l’espacement de la grille et l’enregistrement ont déjà été initialisés ; utilisez spacing et registration pour remplacer ces valeurs.
region (str ou liste) - xmin/xmax/ymin/ymax[+r][+uunit]. Spécifie la région d’intérêt.
search_radius (str) - Définit le rayon de recherche qui détermine quels points de données sont considérés comme proches d’un nœud.
outgrid (str) - Facultatif. Nom du fichier de sortie netcdf avec l’extension .nc pour stocker la grille.
empty (str) - Facultatif. Définit la valeur assignée aux nœuds vides. Par défaut, NaN.
sectors (str) - sectors[+mmin_sectors]|n. Facultatif. La zone de recherche circulaire centrée sur chaque nœud est divisée en secteurs sectors. Les valeurs moyennes ne seront calculées que si toutes les valeurs se trouvent à l’intérieur d’au moins min_sectors secteurs pour un nœud donné. Les nœuds qui ne satisfont pas à ce test reçoivent la valeur NaN (mais voir empty). Si +m est omis, min_sectors est défini pour être au moins 50% des secteurs (c’est-à-dire arrondi à l’entier supérieur) [Par défaut, une recherche de quadrant avec une couverture à 100%, c’est-à-dire sectors = min_sectors = 4]. Notez que seule la valeur la plus proche par secteur est prise en compte pour le calcul de la moyenne ; les points plus éloignés sont ignorés. En revanche, utilisez sectors= »n » pour appeler l’algorithme du voisin le plus proche de GDAL.
verbose (bool ou str) -
Sélectionne le niveau de verbosité [Par défaut, w], qui module les messages écrits sur stderr. Choisissez parmi 7 niveaux de verbosité :
q - Silencieux, aucun message d’erreur fatale n’est produit.
e - Messages d’erreur uniquement.
w - Avertissements [Par défaut].
t - Temps d’exécution (rapports sur les durées d’exécution des algorithmes intensifs en temps).
i - Messages informatifs (identiques à verbose=True).
c - Avertissements de compatibilité.
d - Messages de débogage.
aspatial (bool ou str) - [col=]nom[,…]. Contrôle la façon dont les données aspatiales sont gérées lors de l’entrée et de la sortie. La documentation complète se trouve à l’adresse https://docs.generic-mapping-tools.org/latest/gmt.html#aspatial-full.
binary (bool ou str) -
i|o[ncols][type][w][+l|b]. Sélectionne une entrée binaire native (en utilisant binary= »i ») ou une sortie binaire (en utilisant binary= »o »), où ncols est le nombre de colonnes de données de type, qui doit être l’un des suivants :
c - int8_t (char signé d’1 octet)
u - uint8_t (unsigned char d’1 octet)
h - int16_t (entier signé de 2 octets)
H - uint16_t (entier non signé de 2 octets)
i - int32_t (entier signé de 4 octets)
I - uint32_t (entier non signé de 4 octets)
l - int64_t (entier signé de 8 octets)
L - uint64_t (entier non signé de 8 octets)
f - float à simple précision de 4 octets
d - double à double précision de 8 octets
x - utiliser pour ignorer ncols n’importe où dans l’enregistrement
Pour les enregistrements avec des types mixtes, ajoutez des combinaisons supplémentaires de ncols type séparées par des virgules (par exemple, « 2i,1f » pour 2 colonnes entières suivies d’une colonne à précision simple transformée en virgule flottante). Les modificateurs suivants sont pris en charge :
w après n’importe quel élément pour forcer l’inversion des octets .
+l|b pour indiquer que l’intégralité du fichier de données doit être lu en tant que petit ou grand endian, respectivement.
La documentation complète se trouve à l’adresse https://docs.generic-mapping-tools.org/latest/gmt.html#bi-full.
nodata (str) - i|onodata. Remplace des valeurs spécifiques par NaN (pour les données tabulaires). Par exemple, nodata= »-9999 » remplacera toutes les valeurs égales à -9999 par NaN lors de l’entrée et toutes les valeurs NaN par -9999 lors de la sortie. Préfixez i à la valeur nodata pour les colonnes d’entrée uniquement. Préfixez o à la valeur nodata pour les colonnes de sortie uniquement.
find (str) - [~] « pattern » | [~]/regexp/[i]. Ne transmet que les enregistrements qui correspondent au motif ou aux expressions régulières données [Par défaut, traite tous les enregistrements]. Préfixez ~ au motif ou à l’expression régulière pour ne transmettre que les expressions de données qui ne correspondent pas au motif. Ajoutez i pour une correspondance insensible à la casse. Cela ne s’applique pas aux en-têtes ou aux en-têtes de segment.
coltypes (str) - [i|o] colinfo. Spécifie les types de données des colonnes d’entrée et/ou de sortie (données temporelles ou géographiques). La documentation complète se trouve à l’adresse https://docs.generic-mapping-tools.org/latest/gmt.html#f-full.
gap (str or list) -
x|y|z|d|X|Y|Dgap[u][+a][+ccol][+n|p]. Examine l’espacement entre les points de données consécutifs afin d’imposer des interruptions dans la ligne. Pour spécifier plusieurs critères, fournissez une liste où chaque élément contient une chaîne décrivant un ensemble de critères.
x|X - définit une interruption lorsqu’il y a un changement suffisamment important dans les coordonnées x (en majuscules pour utiliser les coordonnées projetées).
y|Y - définit une interruption lorsqu’il y a un changement suffisamment important dans les coordonnées y (en majuscules pour utiliser les coordonnées projetées).
d|D - définit une interruption lorsqu’il y a une distance suffisamment grande entre les coordonnées (en majuscules pour utiliser les coordonnées projetées).
z - définit une interruption lorsqu’il y a un changement suffisamment important dans les données z. Utilisez +ccol pour changer la colonne de données z [Par défaut, la colonne est 2 (c’est-à-dire la 3e colonne)].
Une unité u peut être ajoutée à l’intervalle spécifié :
Pour les données géographiques (x|y|d), l’unité peut être arc-d(egrés), m(inutes) et s(econdes), ou (m)è(tres), f(eet), k(ilomètres), M(iles) ou n(autical miles) [Par défaut, c’est (m)e(tres)].
Pour les données projetées (X|Y|D), l’unité peut être i(nches), c(entimètres) ou p(oints).
Ajoutez le modificateur +a pour spécifier que tous les critères doivent être remplis [par défaut, des interruptions sont imposées si au moins un critère est rempli].
Les modificateurs suivants peuvent être ajoutés :
+n - spécifie que la valeur précédente moins la valeur actuelle de la colonne doit dépasser l’intervalle pour qu’une interruption soit imposée.
+p - spécifie que la valeur actuelle moins la valeur précédente doit dépasser l’intervalle pour qu’une interruption soit imposée.
header (str) -
[i|o][n][+c][+d][+msegheader][+rremark][+ttitle]. Spécifie que le fichier d’entrée et/ou de sortie comporte n enregistrements d’en-tête [Par défaut, c’est 0]. Préfixez i si seule l’entrée principale doit comporter des enregistrements d’en-tête. Préfixez o pour contrôler l’écriture des enregistrements d’en-tête, avec les modificateurs suivants pris en charge :
+d pour supprimer les enregistrements d’en-tête existants.
+c pour ajouter un commentaire d’en-tête avec les noms de colonnes à la sortie [Par défaut, il n’y a pas de noms de colonnes].
+m pour ajouter un en-tête de segment segheader à la sortie après le bloc d’en-tête [Par défaut, il n’y a pas d’en-tête de segment].
+r pour ajouter un commentaire de remarque à la sortie [Par défaut, aucun commentaire]. La chaîne de remarque peut contenir n pour indiquer des sauts de ligne.
+t pour ajouter un commentaire de titre à la sortie [Par défaut, aucun titre]. La chaîne de titre peut contenir n pour indiquer des sauts de ligne.
Les lignes vides et les lignes commençant par # sont toujours ignorées.
incols (str or 1-D array) -
Spécifie les colonnes de données pour l’entrée principale dans un ordre arbitraire. Les colonnes peuvent être répétées et les colonnes non répertoriées seront ignorées [Par défaut, lit toutes les colonnes dans l’ordre, en commençant par la première (c’est-à-dire la colonne 0)].
Pour un tableau 1-D : spécifiez les colonnes individuelles dans l’ordre d’entrée (par exemple, incols=[1,0] pour la deuxième colonne suivie de la première colonne).
Pour str : spécifiez les colonnes individuelles ou les plages de colonnes dans le format start[:inc]:stop, où inc est par défaut 1 s’il n’est pas spécifié, avec les colonnes et/ou les plages de colonnes séparées par des virgules (par exemple, incols= »0:2,4+l » pour entrer les trois premières colonnes suivies de la colonne 5e transformée logarithmiquement). Pour lire à partir d’une colonne donnée jusqu’à la fin de l’enregistrement, laissez la fin de la plage de colonnes. Pour lire du texte supplémentaire, ajoutez la colonne t. Ajoutez le mot number à t pour ingérer uniquement un seul mot à partir du texte supplémentaire. Au lieu de spécifier des colonnes, utilisez incols= »n » pour simplement lire une entrée numérique et ignorer le texte supplémentaire. Vous pouvez éventuellement ajouter l’un des modificateurs suivants à chaque colonne ou plage de colonnes pour transformer les colonnes d’entrée :
+l pour prendre le logarithme décimal des valeurs d’entrée.
+d pour diviser les valeurs d’entrée par le facteur de diviseur [par défaut, 1].
+s pour multiplier les valeurs d’entrée par le facteur d’échelle [par défaut, 1].
+o pour ajouter le décalage donné aux valeurs d’entrée [par défaut, 0].
registration (str) - g|p. Forcer l’enregistrement des nœuds sur une grille (g) ou sur des pixels (p) [Par défaut, c’est g(enregistrement sur grille)].
wrap (str) - y|a|w|d|h|m|s|cperiod[/phase][+ccol]. Convertir la coordonnée x d’entrée en une coordonnée cyclique ou une colonne différente si elle est sélectionnée via +ccol. Les transformations de coordonnées cycliques suivantes sont prises en charge :
y - cycle annuel (normalisé)
a - cycle annuel (mensuel)
w - cycle hebdomadaire (jour)
d - cycle journalier (heure)
h - cycle horaire (minute)
m - cycle minute (seconde)
s - cycle seconde (seconde)
c - cycle personnalisé (normalisé)